Build System At Genus AI
Having worked at two startups from day one - YPlan and Genus AI - there is this exciting period of high-velocity and high-productivity when changes are fast, staging is the development machine, and release is just a few quick commands away. It is energizing, invigorating, and rewarding as you can see the prototype, MVP, beta, or v1, materialize almost out of thin air.
Yet, as the project and the team grows, this process gradually becomes slower and more complex. There is more to coordinate with the team, the stakes of making a change are also getting higher. If unchecked, this emergent friction results in release times of one day, a week, maybe even a month. In some cases that may be fine, but I am a firm believer that it is unacceptable for a startup to have a lead time1 longer than a day.
My obsession to ship fast comes from seeing first-hand, at YPlan, how customers, both internally (tools) and externally (product), light up when they see their problem fixed or solved sooner, rather than later. Joining Genus AI as the first engineer in 2018 I did enjoy those vigorous first months, and as the talented Adam Chainz (of the Speed Up Your Django Tests fame) later briefly joined us - we both wanted to keep the same pace. We not just succeeded, but even improved the setup, as compared to that of YPlan. Here’s how it looks in 2020.
Builds And Deployment Frequency
This graph shows monthly build and deployment counts for the past 15months.
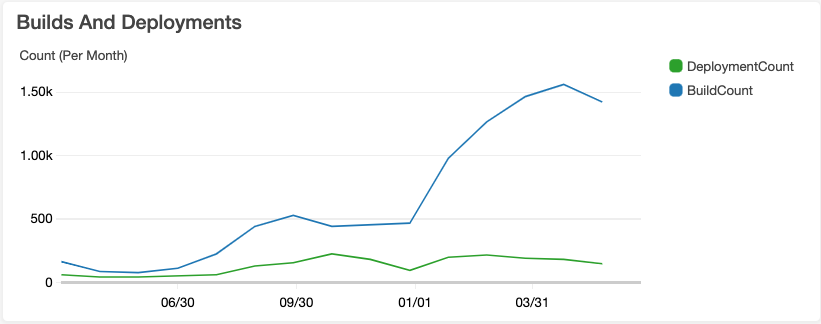
Some key changes visible in the graph:
- There’s a dip before July 2019, when I was a single engineer behind the project and focus was on hiring the team.
- From July 2019, the engineering team size increased by one person roughly every month until October. The builds and deployments gradually increased and plateaued at that time.
- January 2020 is when our first full-stack engineer joined the team and we started rapidly converting the website from hard to maintain Django templates, to a React-based website running on top of a GraphQL API.
Most recently we have been doing about 1500 test builds and between 150 and 200 deployments per month, or, assuming 20 workdays per month, about 75 test builds per day and 10 deployments. That is not a bad frequency for a team of five people, considering that our industry-standard, according to DevOps Research Association2 (DORA), is between once a week and once a month.
Something that might be interesting to look at is a further breakdown of builds and deployments.
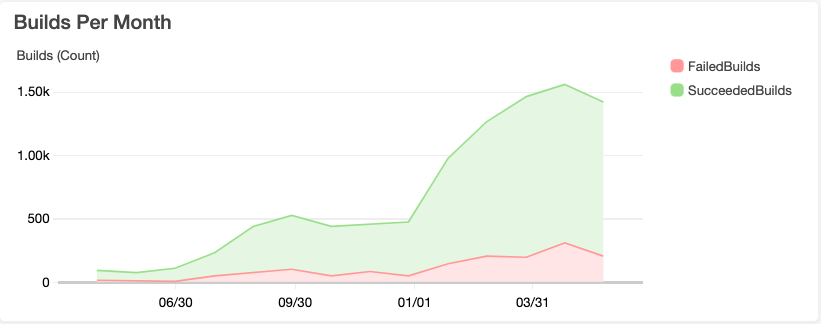
It largely varies, but we aim to submit our work early for review feedback. Sometimes changes may not even pass all the tests, sometimes the feedback involves partial adjustments. One thing worth mentioning is that we try to keep our build hierarchy flat. Here’s what I mean - whereas if applications A & B both depend on some package C. If A or B are changed - only their test builds start. If C is changed - A, B, and C test builds start; this primarily works because we use a monorepo and explains the high succeeded-to-failed build ratio in the graph. One change may result in more than one test build.
Next up, is the breakdown of deployments.
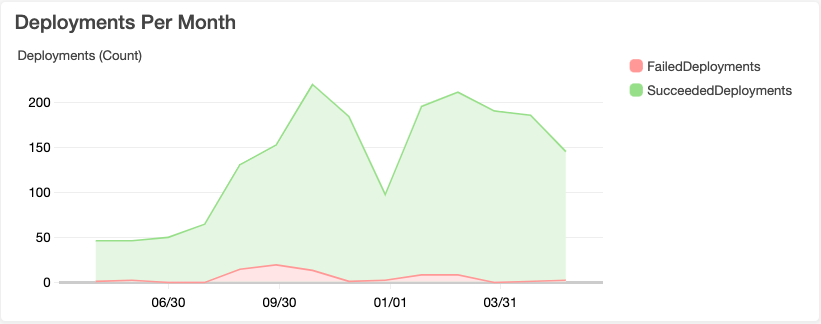
A really important factor in shipping to production is the confidence and safety of doing so. This is where a continuous deployment pipeline comes into play. Deployments at Genus AI are done in two all-at-once stages - backend (asynchronous workers) and frontend (website and API). After deployment to the backend, final verification checks are done, and if successful - the process continues with deployment to frontend. These checks can fail and backend operates at a reduced capacity - part or all of it is not working. Such failures are represented by the failed deployments in the graph. However, the frontend remains operational. It is certainly not perfect, and I imagine we will have to improve this in the future.
This deployment approach is primarily enabled by the habit of doing small changes. Small changes, individually, have a small impact radius. Fixing an issue majority of the time is a simple revert, and releasing it takes less than 15mins, but more on that later. If something went through and broke frontend - we usually looked for ways to catch regressions at test build time. That is a contributing factor, why our failed deployments are relatively low, but failed builds, in the “Builds per Month” graph, quite high.
When new team members join, they have to do a warm-up exercise on day one and get some code deployed as part of that. The warmup exercise ends with a note: “Don’t worry if something doesn’t work and feel free to make mistakes.” On one side, the purpose is to get the new person ship code fast, and not get terrified of failure. At the same time, it is a test of the verifications done in the deployment pipeline. As the graph shows - it stopped deployment of a few changes that would’ve broken frontend.
Time To Production
According to DORA, the industry average lead time, from code accepted and committed to deployed to production, is between once a week and once a month. Below is the average Genus AI build and deployment times for the last 15 months. It is less than five minutes:
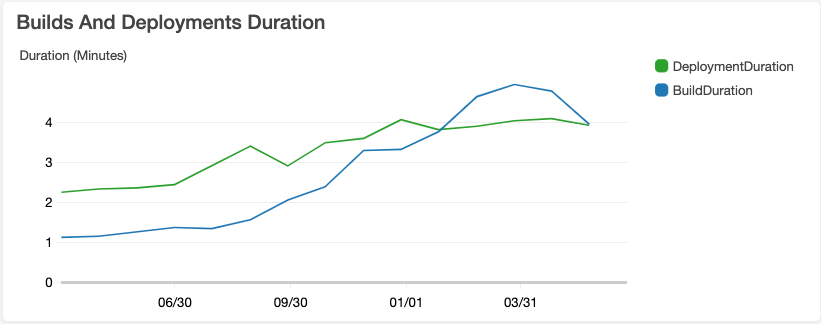
It is worth emphasizing this average does not capture variability. We do have some builds and deployments that take more time. Most of this speed in test builds is achieved by executing multiple different types of builds, e.g. code tests, integration tests, migration checks, security checks, merge checks, in parallel. An interesting effect of this speed is that our major bottleneck to deploying code is not the release process, but the code review process. However, bottleneck being there allows some flexibility: trivial changes - go out fast; changes that are chunkier - may take longer. Hence why breaking things down (Part I & Part II) is so important for us.
Availability
We operate on a very loosely interpreted rule - “it should not break twice.” We accept the fact that things will break, and when they do, we triage it as something low-impact, and keep track of occurrences openly, or high-impact, and look for ways to fix it immediately, and with a regression test.
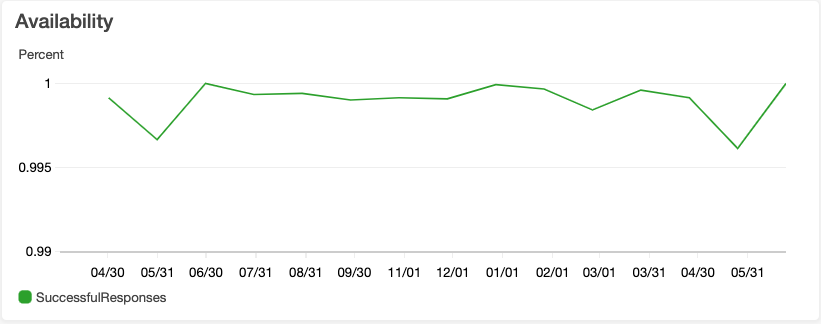
As mentioned earlier, we do have partial failures regularly, that get reverted. The graph above shows the percentage of successful responses vs 5xx errors. It fluctuates just below 100%, with the lowest point being 99.6%. However, considering the test and deployment pipeline weeds a lot of the issues, and the changes we do are small, the issues causing dips in this graph are usually low-impact, localized to a specific part of the product, result in partial performance downgrade or a delayed background task processing.
Another important factor is the engineering team is located in a timezone significantly ahead of our clients. We use this to our advantage - failures are fixed before they become visible. Considering our lead time to production is about 15 minutes, we usually roll-forward issues with revert commit, then take time to reflect, and implement a fix.
We are small, growing, startup so this nimbleness allows us to make a trade-off like that. A larger-scale B2C startup, or a very large established product, might not have such luxury, but we do for now and use it to our advantage. Considering the focus of the industry towards high availability, it is easy to forget that sometimes the cost of not-fixing something (or letting it fail for a short time) is lower than the cost of not implementing an important product improvement somewhere. I think the affinity towards 0% downtime at a time when product is growing, without any regard to context, is a waste of resources, but mileage may vary case-by-case.
The Setup
At a very high level - these are the principal components enabling all of the mentioned traits.
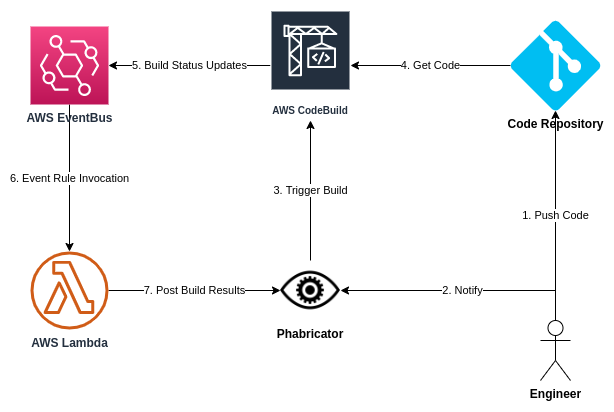
We use a monorepo codebase for the same advantages Google
does 3,
it is just a natural thing to start with on a new project, and I had seen it
work. Phabricator is the tool for code reviews and build orchestration. Arcanist
command-line tool (arc) provides a very simple developer workflow:
Engineers work on code locally, on top of the trunk, and when they want to test
it automatically and/or get their code reviewed, they run arc diff. This
command submits the changes for review, as well as triggers the automated build
and testing pipeline. Engineers can break down big changes into a
stack4 of
smaller ones. When changes are reviewed and accepted, the engineer runs arc land, and deployment to production is taken care of automatically.
It is so boring5, that since the inception in 2018, this setup required virtually zero maintenance and scaled well with the team and the product. The only changes required are adjustments in build commands or adding/removing additional builds, once in a while.
Cost
We religiously tag our resources on AWS, so Cost & Usage Report section in the AWS Console can show a pretty accurate report for the build system. The 0 in June 2019 is due to the cost being covered by AWS credits.
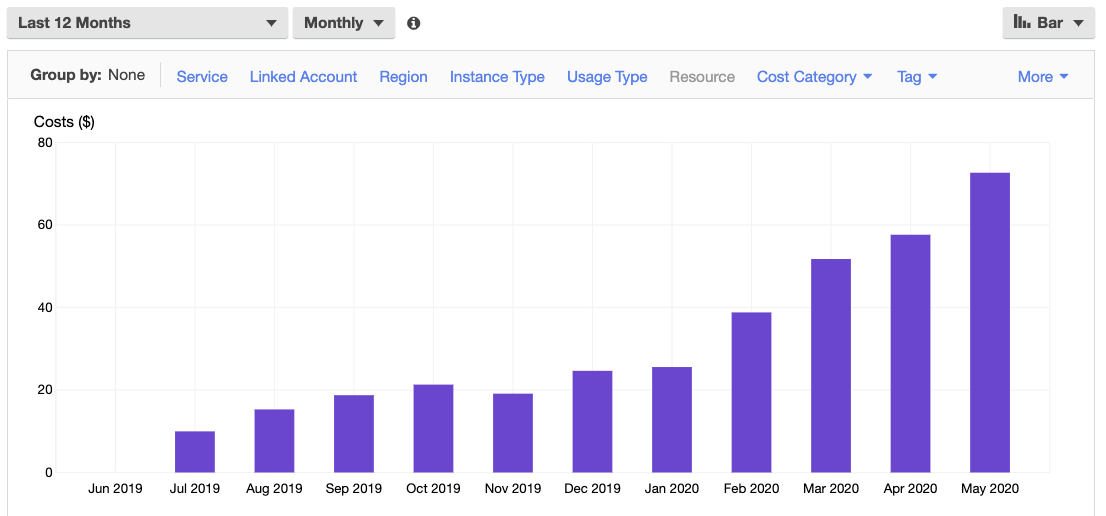
Back in 2018, we invested about 2hours at the end of the day for two weeks to build this. The low cost of this, and the fact that this system scaled so well for 2 years in a row at such a low monetary and maintenance cost - it is not a bad investment.
Interestingly, this might not have happened. When we were setting up the CI/CD pipeline in 2018, Phabricator had a ready-made CircleCI plugin, that used APIv1, that we installed. However, CircleCI decided to sunset its APIv1 and gave about 30 days to migrate. Since we didn’t feel confident writing robust PHP - rewriting the plugin was not an option. We decided to look for alternatives and settled on AWS CodeBuild.
Conclusion
I wanted to show you that for a small and nimble product startup build and deployment pipeline does not require a heavy upfront investment, expensive 3rd party services, dedicated build clusters, Kubernetes, or toolchains large organizations use. What is needed is a robust way to launch a build container, execute commands, and get the results in some form. That’s what AWS CodeBuild, AWS EventBus, AWS Lambda, and Phabricator - a boring infrastructure - enabled us to do at Genus AI: focus on building a cool product.
[Footnotes]
Lead Time - time from accepted code change to release to production. ↩︎
DORA - DevOps Research Association. A Google owned research body researching and promoting good DevOps practices. ↩︎
Why Google Stores Millions Lines Of Code in a Single Repository from Communications of the ACM:
- Unified versioning, one source of truth;
- Extensive code sharing and reuse;
- Simplified dependency management;
- Atomic changes;
- Large-scale refactoring; (our use-case: Large Scale Refactoring With PyBowler)
- Collaboration across teams;
- Flexible team boundaries and code ownership; and
- Code visibility and clear tree structure providing implicit team namespacing.
Stacked Diffs Versus Pull Requests - Jackson Gabbard has done an excellent write-up. ↩︎
Boring Technology Club - I am a massive fan. ↩︎