On Large Language Models
I’ve been asked about my thoughts on Large Language Models (LLMs), so I’ve decided to put together a blog post to share my reflections. These opinions are not unique; they are based on social media commentary, newsletters, blog posts, videos, and my own experiences with LLMs like GPT v3.5 and v4 for work and personal projects.
Hype Cycle
We are currently experiencing an unprecedented hype cycle, and with few signs of the Trough of Disillusionment, it appears we are still approaching the Peak of Inflated Expectations. This is largely due to OpenAI’s increasingly impressive GPT models, which are truly remarkable and should not be dismissed or underestimated.

The current hype has led to concerns about AI-based tools replacing jobs, particularly in software engineering. My own anxiety subsided after using the models, realizing that while they are great tools to assist with my work, they cannot replace a skilled software engineer. Here’s a relevant video:
The author’s conclusion lacks self-reflection, as ChatGPT’s output shouldn’t be considered senior-level. A junior engineer could produce similar results with proper documentation and guidance from an experienced engineer. While it’s impressive that the machine learning model generated the output from a natural language request, it was directed by a professional - who the show host clearly is.
Real Life Trends Flatten
In the book Factfulness, Hans Rosling discusses the “straight line instinct,” where people assume upward trends will continue indefinitely, which is often not the case. ChatGPT’s performance will eventually plateau, as there are limits to the improvements a machine learning model can achieve from a given dataset. The focus will likely shift towards model specialization or expanding its capabilities to include visual, audio, or even tactile/sensory input.
Specialization is already evident in products like Copilot X, a ChatGPT v4-driven programming assistant, and in the integration with Microsoft Office for transcribing online meetings and drafting presentations. Expanding modes of operation can be seen in ChatGPT’s latest version, which supports image interpretation.
Training Data
We can't all use AI. Someone has to generate the training data.
— Paul Graham (@paulg) March 14, 2023
The performance plateau is influenced by training data. Commercial datasets are often licensed rather than sold, effectively as a subscription for dataset upkeep. OpenAI likely relies on such datasets, which carries a risk of license revocation. A similar situation occurred when movie rights holders, like Disney, recognized the potential for their own streaming platforms and revoked licenses from platforms like Netflix.
I don’t suggest everyone will create their own LLMs, but data providers may seek a share of OpenAI’s profits through licensing fees. Alternatively, a competitor could secure exclusive licensing, limiting OpenAI’s data access. While hypothetical, such scenarios could have lasting effects on the product.
Context Window
I conducted an experiment with ChatGPT on my pet project, inspired by Simon Willison’s ReAct pattern reimplementation. I provided commands for the model to list files, read files, and apply a diff within my project directory, and instructed it to follow a Thought, Action, PAUSE, Observation loop. I asked ChatGPT to add a simple feature involving installing a dependency, updating a model, and modifying a form template. The following results were consistently observed after multiple attempts:
ChatGPT inferred the need to read the file, but once provided, it forgot the original request, regardless of file size optimization. The file was a Django models file, initially 12KB and ~250 lines, which I reduced to ~2KB. ChatGPT has a limitation of the size of input it can process, called the “context window.” This “context window” affects its ability to remember experiences beyond a certain input size, restricting the model’s capacity to recall prior instructions.
These limitations may not be fundamental, and could be overcome eventually. However, if the context size depends on finite resources (e.g., server memory), increasing the context window to handle larger inputs could raise the service cost, potentially making human labor more economical. Of course, I am speculating.
Experience And Tribal Knowledge
In software engineering and other fields there is a concept called “tribal knowledge,” something that is known but not explicitly documented. For example, tribal knowledge represents hard-earned lessons accumulated over a career, encompassing individual projects and skillsets. By definition it is difficult to train models on it. Some information may be implicitly encoded in code, but without sufficient documentation explaining ‘why’ certain choices were made, the model can only guess. Humans have a significant competitive advantage in this area over machines.
ChatGPT’s current context window is 32K tokens (about 750 words per 1000 tokens). In contrast, my context window spans 23+ years as a hobbyist and 16 as a professional. While my recall is inferior to ChatGPT’s, my precision in distinguishing good from bad answers is higher. Together, we form a more effective combination than either of us alone.
Groundhog Day
Observing the startup scene over the past 15-20 years, I’ve learned that disruptors often become the companies they disrupted. Examples include London cabs now being more accessible than Uber, Netflix contemplating ads in shows just like cable TV, Airbnb resembling Booking.com with added cleaning fees and faceless corporate hosts, and Facebook evolving into an oversized bulletin board. In time, OpenAI will transform into a mishmash of the companies it will replace.
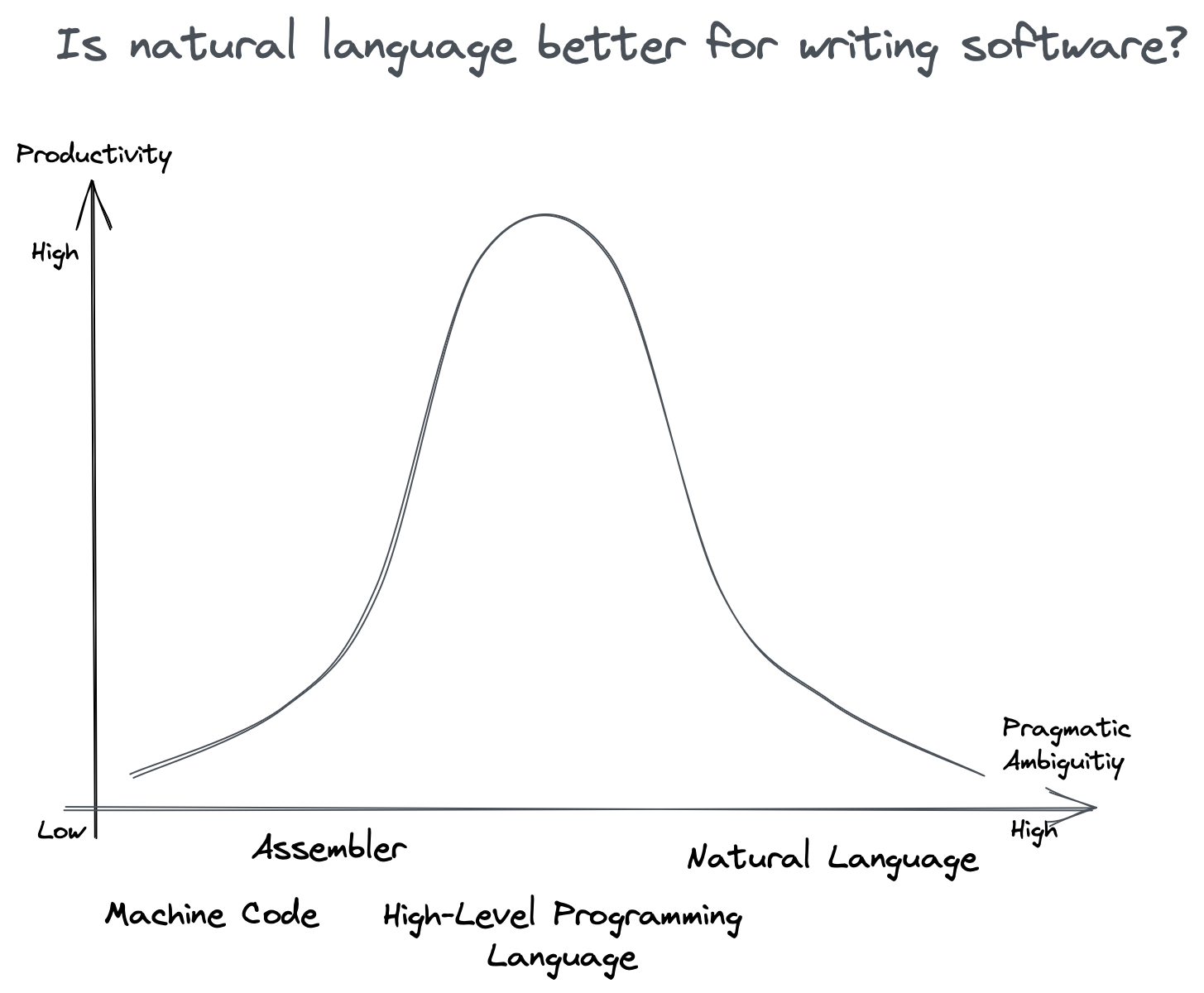
Natural Language Is Not A Programming Language
Early in my career, writing specifications for software engineers taught me that natural language is not the ultimate programming language. Asserting otherwise disregards decades of computer science research. Natural language is inherently ambiguous; while you could request “a TikTok for restaurant chefs,” the initial result likely won’t meet your expectations. Adjusting the app may resemble a product manager’s role, but there’s a point where using a context-free language, a programming language, is more efficient. A human programmer will be needed to translate requirements into code accurately the first time, even if not necessarily faster.
Prompt Engineering
Initially, I found prompt engineering to be a dubious idea, then intriguing, and now I’m uncertain. If language models remain black boxes, prompt engineering could resemble astrology or alchemy, a pseudo-scientific approach to coaxing desired outputs from ML models. However, if OpenAI offers integration points centered around prompt engineering, like rapidly testing significant words or conversations, a burgeoning new industry could emerge. Until then, sustaining investment in prompt engineering roles, which currently involve guesswork, may be challenging once we pass the Peak of Inflated Expectations.
Translators & Dictionaries
Google Translate, like ChatGPT, was a remarkable accomplishment. While it didn’t replace human translators, it replaced dictionaries and made information more accessible globally. Similarly, ChatGPT won’t replace humans but will enable them to do more. However, now may be the worst time to be “the dictionary.”
Career In Software Engineering
In my opinion, the software engineering career path is secure, and it’s now easier to begin. Previously it was a rite of passage. Finding answers required attending university or extensive online searches and reading, but now, answers are a prompt away. However, it’s crucial not to take LLM-generated information at face value and to cross-check. LLMs can confidently provide misleading information, and even ChatGPT 4 veers off-course in 30-50% of my own requests, necessitating further instruction or rephrasing.
For example, I am comfortable delegating simple tasks to LLMs when I can easily verify the output. As Andy Grove said, “delegation without supervision is abdication.” For instance, I asked ChatGPT for a regular expression to create a complex input validator in a Django project. I tested the provided regex and asked for edge cases, validating them. ChatGPT generated a validator class that required tweaking. After adjusting and testing, the task was complete in 15 minutes, significantly faster than if I were to do it from scratch. This allowed me to move onto more engaging tasks, making it a win!
Fetishisation of AI
There’s a recurring theme I call the “fetishisation of AI,” which assumes AI is or will be better than humans in every situation. This belief is evident when people think decisions are correct simply because AI made them or when they assume AI will always be the preferred choice. For example, a recent article suggested the demand for human software engineers would collapse as AI could fulfill everyone’s needs. This notion is false, as previously discussed regarding the limitations of natural language for building software.
Banning LLM Development
As I was writing this, a group of notable people signed a petition for OpenAI to stop developing AI. I categorically disagree with the basic idea, regardless of who is calling for it. Banning is a reactive response. It is impossible to “ban and investigate the impact.” The only way to investigate the impact is to go through the development process, carefully assessing the results at each step. That is a proactive approach.
Threshold For Concern
I’ll become concerned when an LLM can create a product without active human direction, seeking feedback along the way. At that point, it will be a fully autonomous agent, and it’s unclear what will happen. We may end up building tools for AI to access more information rather than building tools to help us be more productive.
Someone is already experimenting with this, but the results are limited:
Huh, well that's starting to work... 🤔
— Yohei (@yoheinakajima) March 26, 2023
Kind of just goes on... and on... building and reprioritizing a task list for itself... pic.twitter.com/whcsSNdBHz
The Future Is Bright
LLMs will democratise programming as a craft, and will lower the entry bar for a new generation of entrepreneurs. If you find programming hard, but have enough patience to describe what you want and the skills to glue the bits together - you can build any prototype faster than ever.
LLMs will augment software engineering to a new level. There will undoubtedly be bumps along the road, but in the end we will use ChatGPT more than we will be abused by it.
LLMs will be the world’s most patient but unreliable teachers. As long as you are willing to verify what it says is true, you’ll learn.
I also must make a confession. I wrote this article and a good friend reviewed it and provided feedback. At the same time I am an ESL (Eglish as a Second Language) speaker and I am very conscious that my writing can be excessively verbose, repetitive or non-idiomatic. So you can feel where this is going - I asked ChatGPT to make each paragraph shorter and more concise, also explaining to me the changes it made and why. I still had to tweak the result, but I think overall it did a great job.
Therefore, maybe just like Google Translate made the world’s information more accessible to everyone, one of the best use-cases for LLMs will be, to make everyone’s ideas more accessible to the world.